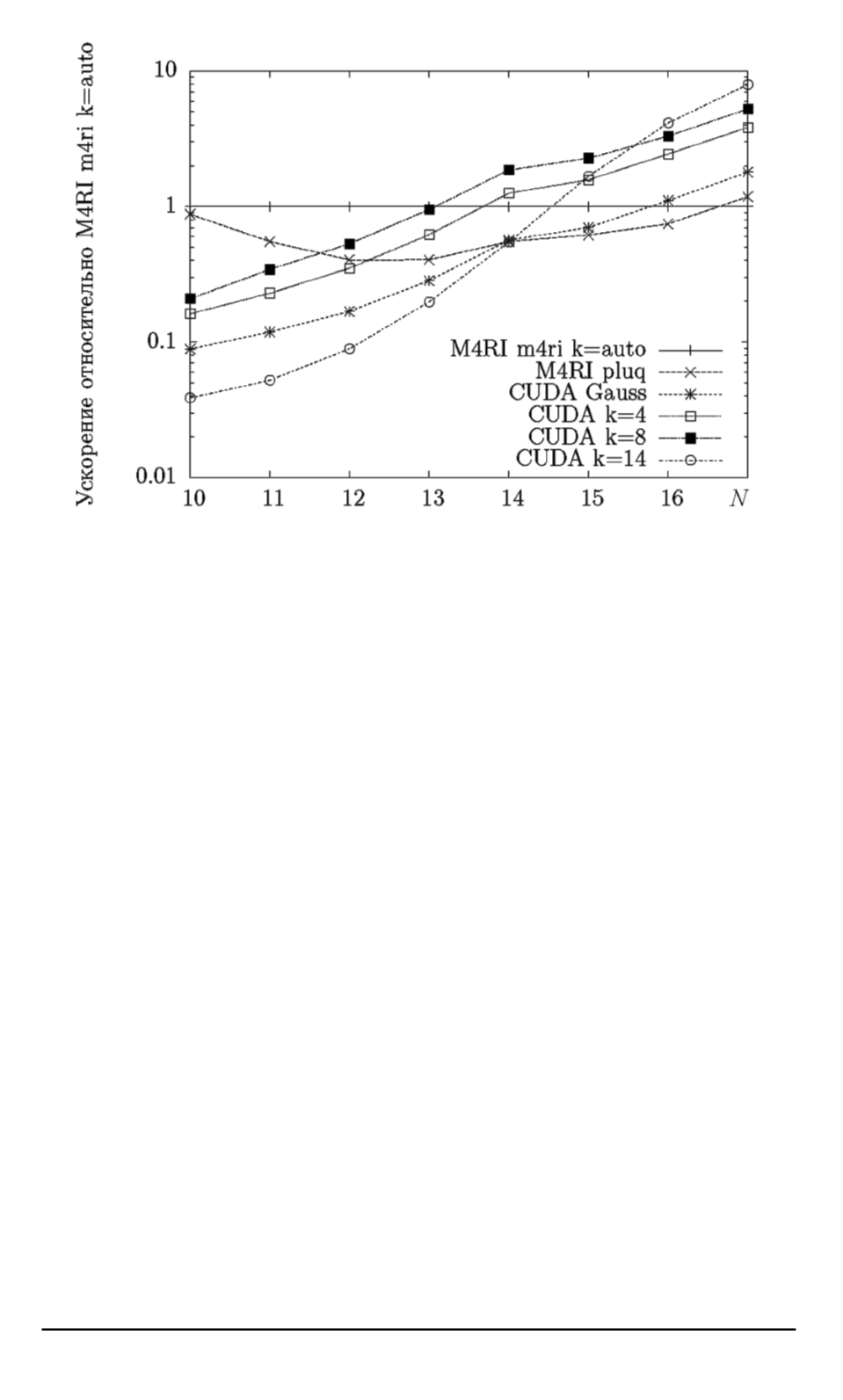
Рис. 3. Относительное время работы при обработке матриц размера
2
N
×
2
N
разными методами
В [3] указано, что при незначительном отклонении от использу-
емой оценки оптимального значения
k
скорость обработки мало от-
личается от оптимальной. Для малых матриц слишком велика доля
временных затрат, не связанных напрямую с выполнением алгорит-
ма, что не позволяет делать выводов по поводу этого утверждения. На
больших матрицах видно, что оптимальное
k
оценке
log
2
m
не соответ-
ствует. Это связано с аппаратными особенностями графической карты
и различных видов памяти, используемых в реализации алгоритма.
Более того, эти значения различны для разных видеокарт.
Что касается сравнения с реализацией [6], выполненной с исполь-
зованием той же технологии, провести его в полной мере не удалось
из-за неполноты результатов, представленных в этой работе. Тем не
менее, приведенный в ней результат — 71 с для матрицы
64000
×
65536
,
полученный на видеокарте GeForce GTX 480, во много раз хуже луч-
шего для данной реализации.
Отдельно отметим вопрос энергопотребления вычислительной си-
стемы во время работы алгоритма. Необходимые измерения проводи-
лись с помощью простого ваттметра, входящего в конструкцию имев-
шейся системы. Хотя он и не является профессиональным измеритель-
ным инструментом, но позволяет приближенно оценить изменение
энергопотребления всего компьютера во время расчетов относительно
состояния бездействия.
Реализация метода “четырех русских” на CUDA отличается ста-
бильным энергопотреблением на протяжении всего времени расче-
58
ISSN 1812-3368. Вестник МГТУ им. Н.Э. Баумана. Сер. “Естественные науки”. 2013. № 1


